第 1 章 數據分析競賽是什麼?
1.1 什麼是數據分析競賽?
1.1.1 數據分析競賽的目的
1.1.2 提交預測結果與排行榜 (Leaderboard)
1.1.3 組隊參賽
1.1.4 獎金、獎品
1.2 Kaggle 平台簡介
1.2.1 Kaggle
1.2.2 Rankings (排名、頭銜制度)
1.2.3 Notebooks
1.2.4 Discussion
1.2.5 Datasets
1.2.6 Kaggle API
1.2.7 Newsfeed
1.2.8 實際舉辦過的數據分析競賽類別與案例
1.2.9 數據分析競賽的形式 (format)
1.3 從開始參加數據分析競賽到結束
1.3.1 參加數據分析競賽
1.3.2 同意規定和條約
1.3.3 下載資料
1.3.4 產生預測值
1.3.5 提交預測值
1.3.6 查看 Public Leaderboard
1.3.7 選擇最終預測值
1.3.8 查看 Private Leaderboard
1.4 參加數據分析競賽的意義
1.4.1 獲得獎金
1.4.2 獲得頭銜或排名
1.4.3 使用實際資料進行分析的經驗/技術
1.4.4 建立和其他資料科學家的交流
1.4.5 獲得就業機會
1.5 贏得優勝的秘訣
1.5.1 任務和評價指標 (Metric)
1.5.2 建立特徵
1.5.3 建立模型
1.5.4 評價模型
1.5.5 模型調整
1.5.6 集成學習 (Ensemble Learning)
1.5.7 數據分析競賽的流程
第 2 章 任務與評價指標
2.1 數據分析競賽的任務種類
2.1.1 迴歸任務 (Regression)
2.1.2 分類任務 (Classification):二元分類與多分類
2.1.3 推薦任務 (Recommendation)
2.1.4 圖像資料任務
2.2 數據分析競賽的資料集 (Dataset)
2.2.1 表格資料 (tabular data)
2.2.2 外部資料
2.2.3 時間序列資料
2.2.4 圖像或自然語言等資料
2.3 任務與評價指標
2.3.1 什麼是評價指標 (evaluation metrics)?
2.3.2 迴歸任務的評價指標
2.3.3 二元分類任務的評價指標:預測值為正例或負例的情況
2.3.4 二元分類任務的評價指標:預測值為正例機率的情況
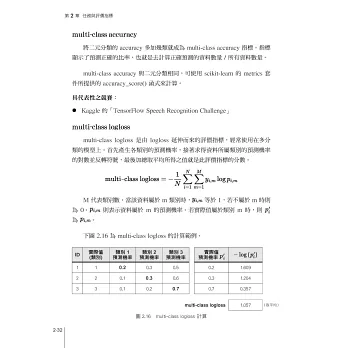
2.3.5 多元分類 (Multiclass Classification) 任務的評價指標
2.3.6 推薦任務的評價指標:MAP@K
2.4 評價指標和目標函數
2.4.1 評價指標和目標函數的差異
2.4.2 自定義評價指標與目標函數
2.5 評價指標的最佳化
2.5.1 最佳化評價指標的方法
2.5.2 最佳化閾值
2.5.3 是否該使用 out-of-fold 來最佳化閾值?
2.5.4 針對預測機率的調整
2.6 最佳化評價指標的競賽實例
2.6.1 balanced accuracy 的最佳化
2.6.2 mean-F1 的閾值最佳化
2.6.3 最佳化 quadratic weighted kappa 閾值
2.6.4 最佳化MAE ─ 使用相似的自定義目標函數
2.6.5 MCC 的近似值:PR-AUC 及模型的選擇
2.7 資料外洩 (data leakage)
2.7.1 在無預期的情況下外洩有利於預測的資訊
2.7.2 驗證機制錯誤所造成的資料外洩
第 3 章 特徵提取
3.1 本章結構
3.2 模型和特徵
3.2.1 模型和特徵
3.2.2 初步 (Baseline) 模型
3.2.3 從決策樹 (Decision Tree) 的角度思考
3.3 缺失值的處理
3.3.1 維持缺失值
3.3.2 以代表值填補缺失值
3.3.3 使用其他變數來預測缺失值
3.3.4 由缺失值來建立一個全新的特徵
3.3.5 認識資料中的缺失值
3.4 數值變數的轉換
3.4.1 標準化 (standardization)
3.4.2 Min-Max 縮放方法
3.4.3 非線性轉換
3.4.4 Clipping
3.4.5 Binning (分組)
3.4.6 將數值轉換為排序
3.4.7 RankGauss
3.5 類別變數的轉換
3.5.1 One-hot encoding
3.5.2 Label encoding
3.5.3 Feature hashing
3.5.4 Frequency encoding
3.5.5 Target encoding
3.5.6 Embedding
3.5.7 處理次序變數
3.5.8 提取類別變數中值的意義
3.6 日期、時間變數的轉換
3.6.1 轉換日期、時間變數的要點
3.6.2 將日期、時間變數轉換為特徵
3.7 變數組合
3.8 結合其他表格資料
3.9 使用統計量
3.9.1 使用基本統計量
3.9.2 使用時間性統計量
3.9.3 限定條件範圍
3.9.4 轉換統計單位
3.9.5 關注商品
3.10 處理時間序列資料
3.10.1 什麼是時間序列資料?
3.10.2 使用比預測資料還舊的資訊
3.10.3 寬表格和長表格
3.10.4 lag 特徵
3.10.5 將資料與時間做連結的方法
3.10.6 可用於預測的資料時間
3.11 降維/非監督式學習特徵
3.11.1 主成分分析 (Principal Component Analysis, PCA)
3.11.2 非負矩陣分解 (Non-negative Matrix Factorization, NMF)
3.11.3 Latent Dirichlet Allocation (LDA)
3.11.4 線性判別分析 (Linear Discriminant Analysis,也叫 LDA)
3.11.5 t-SNE、UMAP
3.11.6 自編碼器(Autoencoder)
3.11.7 群聚分析 (Cluster analysis)
3.12 其他分析技巧
3.12.1 思考資料的運作背景
3.12.2 關注資料間的關係
3.12.3 關注相對值
3.12.4 關注位置資訊
3.12.5 自然語言的處理
3.12.6 自然語言處理方法與應用
3.12.7 運用主題模型 (Topic Model) 來轉換類別變數
3.12.8 處理影像特徵的方法
3.12.9 Decision Tree Feature Transformation
3.12.10 預測匿名化資料轉換前的值
3.12.11 修正錯誤的資料
3.13 從數據分析競賽案例看提取特徵的方法
3.13.1 Kaggle 的「Recruit Restaurant Visitor Forecasting」
3.13.2 Kaggle 的「Santander Product Recommendation」
3.13.3 Kaggle 的「Instacart Market Basket Analysis」
3.13.4 KDD Cup 2015
3.13.5 數據分析競賽中的其他技巧的案例
第 4 章 建立模型
4.1 什麼是模型?
4.1.1 什麼是模型?
4.1.2 建立模型的步驟
4.1.3 模型相關用語及要點
4.2 常用於數據分析競賽的模型
4.3 梯度提升決策樹 (Gradient Boosting Decision Tree, GBDT)
4.3.1 GBDT 概述
4.3.2 GBDT 的特性
4.3.3 主要的 GBDT 套件
4.3.4 使用 xgboost
4.3.5 使用 xgboost 的要點
4.3.6 lightgbm
4.3.7 catboost
4.4 類神經網路
4.4.1 類神經網路概要
4.4.2 類神經網路的特色
4.4.3 類神經網路的主要套件
4.4.4 建立類神經網路模型
4.4.5 Keras 使用方法及套件
4.4.6 類神經網路的參考架構
4.4.7 解法案例 - 類神經網路的新發展
4.5 線性模型
4.5.1 線性模型概要
4.5.2 線性模型的特徵
4.5.3 線性模型的主要套件
4.5.4 建立線性模型
4.5.5 使用線性模型的方法和要點
4.6 其他模型
4.6.1 K - 近鄰演算法 (K-Nearest Neighbor algorithm, KNN)
4.6.2 隨機森林 (Random Forest, RF)
4.6.3 Extremely Randomized Trees (ERT)
4.6.4 Regularized Greedy Forest (RGF)
4.6.5 Field-aware Factorization Machines (FFM)
4.7 模型的其他要點與技巧
4.7.1 資料含有缺失值
4.7.2 特徵數量太多
4.7.3 表格資料中的標籤沒有 1 對 1 時
4.7.4 pseudo labeling
第 5 章 模型評價
5.1 什麼是模型評價?
5.2 一般資料的驗證手法
5.2.1 hold-out 法
5.2.2 交叉驗證
5.2.3 stratified k-fold
5.2.4 group k-fold
5.2.5 leave-one-out
5.3 時間序列資料的驗證手法
5.3.1 時間序列資料的 hold-out 法
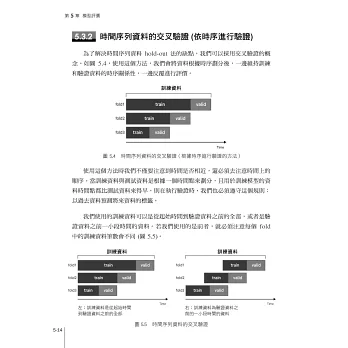
5.3.2 時間序列資料的交叉驗證 (依時序進行驗證)
5.3.3 時間序列資料的交叉驗證 (不管時序直接劃分資料的方法)
5.3.4 驗證時間序列資料的注意事項
5.3.5 Kaggle 的「Recruit Restaurant Visitor Forecasting」
5.3.6 Kaggle 的「Santander Product Recommendation」
5.4 驗證的要點與技巧
5.4.1 進行驗證的目的
5.4.2 模擬劃分訓練資料和測試資料來建立驗證資料
5.4.3 當訓練資料和測試資料的分布不同
5.4.4 利用 Leaderboard 的資訊
5.4.5 驗證資料或 Public Leaderboard 的過度配適
5.4.6 重新提取交叉驗證中每個 fold 的特徵
5.4.7 增加可使用的訓練資料
第 6 章 模型調整
6.1 超參數調整
6.1.1 探索超參數的技巧
6.1.2 調整超參數時的設定
6.1.3 調整超參數的要點
6.1.4 使用貝式最佳化來搜索超參數
6.1.5 GBDT 的超參數及其調整
6.1.6 類神經網路的超參數及其調整
6.1.7 線性模型的超參數及其調整
62 選擇特徵與特徵的重要性
6.2.1 使用單便量統計方法
6.2.2 使用特徵重要性的方法
6.2.3 不斷搜索的方法
6.3 不平衡分類的處理
第 7 章 模型集成
7.1 什麼是集成?
7.2 簡單的集成方法
7.1.1 平均、加權平均
7.2.2 多數決、加權多數決
7.2.3 注意事項及其他技巧
7.3 堆疊 (stacking)
7.3.1 推疊概要
7.3.2 作為建立特徵方法的堆疊
7.3.3 執行堆疊
7.3.4 堆疊的要點
7.3.5 使用 hold-out 資料的預測值來集成
7.4 什麼模型適合集成?
7.4.1 多使用不同類型的模型
7.4.2 改變超參數
7.4.3 改變特徵
7.4.4 改變看待問題的方法
7.4.5 選擇含有堆疊的模型
7.5 數據分析競賽中的集成案例
7.5.1 Kaggle「Otto Group Product Classification Challenge」
7.5.2 Kaggle「Home Depot Product Search Relevance」
7.5.3 Kaggle「Home Credit Default Risk」
附錄A
A.1 數據分析競賽的參考資料
A.2 參考文獻
A.3 本書參考的數據分析競賽


 天天爆殺
天天爆殺  今日66折
今日66折 

































 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來