

 天天爆殺
天天爆殺  今日66折
今日66折 



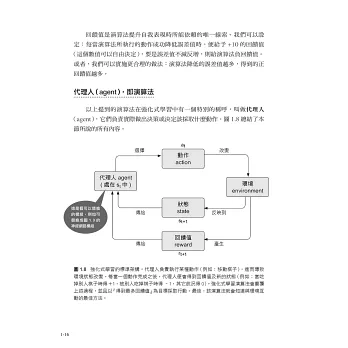





















深度強化式學習 (Deep Reinforcement Learning, DRL),就是將深度學習與強化式學習結合的技術。要讓 AI 應用落地,DRL 是必不可缺的技術。近期由兩位劍橋大學博士所帶領的 Wayve 團隊就利用了 DRL 技術,開發出可以自行從新環境中學習的自動駕駛技術,取代以往完全仰賴感測器的做法。除此之外,工廠內的自動化機器人, 或是打敗世界棋王的 AlphaGo 等,背後運作的演算法也都與 DRL 息息相關。
然而 DRL 的演算法五花八門,讓人看了眼花繚亂。事實上,它們都是為了應付各式各樣的任務而發展出來的改良版本,其核心概念的差異不大,都是立足於 DRL 最基本的 DQN (Deep Q-Network) 之上。因此本書會花費較多的篇幅,一步步帶您把 DQN 的架構完全摸透,並時時提點各個技術細節的重點,讓您可以因應不同的任務或問題,加入適當的技術或技巧來克服,再進一步實作出各種進階的演算法。
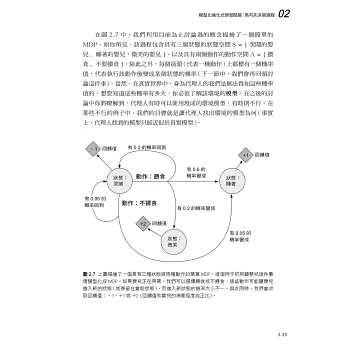
本書一共分成兩篇:基礎篇及進階篇。在基礎篇中,讀者將學習如何從無到有,建構出自己的第一個RL演算法,並用該演算法來解決多臂拉霸機問題。接著,讀者會認識RL中較為經典的演算法,如DQN、策略梯度法、A2C等。同時,各章節皆搭配數個專案,確保讀者可以在學習理論的過程中,培養實作出演算法的能力,不再只是紙上談兵。
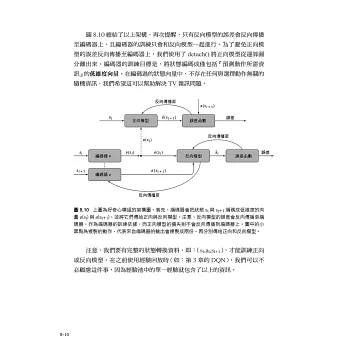
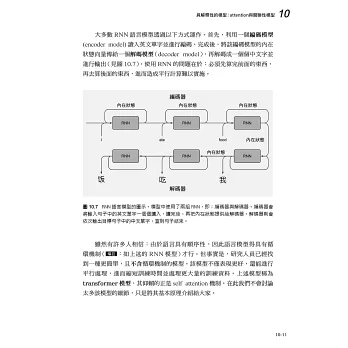
在進階篇中,作者將會介紹較為新穎,也較為複雜的RL演算法。基本上,這些演算法都是以DQN為出發點,再加上特殊的技巧,便能處理現實中的難題。舉個例子,利用平均場DQN,學者們成功模擬出了電子的自旋狀況,進而解決了RL中的多代理人問題。同時,讀者們還將學到如何將attention機制與DQN做結合,進而實作出關聯性DQN(relational DQN),提高演算法的可解釋性。
本書提供了完整的學習架構,循序漸進地介紹各種演算法,包括:
● Deep Q-Network (DQN)
● 策略梯度法(Policy gradient methods)
● 優勢值演員-評論家(Advantage Actor-Critic, A2C)
● 分散式優勢值演員-評論家(Distributional Advantage Actor-Critic, DA2C)
● 進化演算法(Evolutionary algorithm)
● 分散式DQN(Distributional DQN)
● 鄰近Q-Learning(Neighborhood Q-Learning)
● 平均場Q-Learning(Mean field Q-Learning)
● 關聯性DQN(Relational DQN)
除了 RL 相關演算法之外,書中也介紹了近期應用 RL 而發展出來的熱門模型,相信可以提升讀者的硬實力,其中包括:
● 圖神經網路(Graph Neural Network, GNN)
● Transformer模型
● Attention模型(Attention model)
總的來說,本書是最全面、最白話的強化式學習演算法實戰解析。只要您有基本的深度學習知識,並且想要認識強化式學習領域,那麼您就是本書在尋找的合適讀者!
本書特色
●囊括各種強化式學習的基礎及進階演算法,學習架構完整
●適當地補充數學及統計基礎,必要知識直接回顧,不用東翻西找其他資源
●重點整理深度強化式學習的基本架構,打好基礎、再先進的改良模型也看得懂
●以日常案例來實踐 DRL,理解起來事半功倍
●利用Python+PyTorch實作各章專案,不會只是紙上談兵
●所有程式皆已整理成Colab筆記本,一鍵即可檢驗結果
●本書由施威銘研究室監修,內容易讀易懂,並加入大量「編註」與「小編補充」以幫助理解及補充必要知識。







 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來