

 天天爆殺
天天爆殺  今日66折
今日66折 



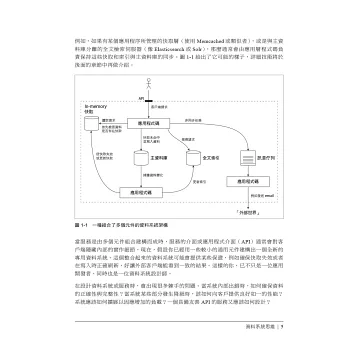




























在當今的系統設計中,資料是許多挑戰的中心。需要克服各種困難,如可擴展性、一致性、可靠性、效率和可維護性。我們有各式各樣的工具可以選擇,包括關聯式資料庫、NoSQL資料儲存、串流或批次處理機以及訊息中介,又該如何做出正確的選擇?如何理解所有這些熱門詞彙?
本書深入剖析各種儲存技術的優缺點,幫助您做全面性的了解。軟體雖然一直變化,但基本的原則始終如一。本書可以幫助軟體工程師與架構師了解如何在實踐中運用這些這些理念,以及如何在現代應用中充分利用資料。
在這本實用而全面的指南中,作者Martin Kleppmann經由研究處理和儲存數據之各種技術的優缺點,幫助您一覽資料世界多樣化的景觀。雖然軟體持續演變,但基本原則始終如一。軟體工程師與架構師可以藉由本書瞭解這些基本的理念,以及如何充分應用資料的方法。
.檢視並學習如何更有效的使用與操作你正在使用的系統。
.了解各種工具的優缺點,並做出明智的選擇。
.圍繞一致性、可擴展性、容錯性和複雜性進行權衡。
.瞭解作為現代資料庫基礎的分佈式系統研究。
.探索並學習主流線上服務的架構。
業界推薦
"本書的問世,是所有相關從業人員之幸。因為即便是資料庫領域的實務專家,也很少有人能像這本書這樣,能夠全面理解資料處理架構的技術全貌,更別說將這些知識一一解說和傳授給其他人。如果你對資料處理架構的設計感興趣,這本書將會是你一定要拜讀的聖經。" -- 錢逢祥(Fred Chien), 寬橋(Brobridge)技術長兼首席架構師
"這本書太棒了,填補了理論跟實務之間的空白。如果十年前就有這本書的話,我可以省掉許多摸索跟犯錯的時間。"--Jay Kreps, Apache Kafka的開發者
"軟體工程師必讀的一本書。這本書是少數能夠完美整合理論與實務的著作,可以幫助開發者做出明智的決定。"--Kevin Scott, 微軟技術長
來自讀者的讚譽
"在準備面試時,這本書對於系統設計的幫助極大"
"程式設計師必讀之作,當你自己設計過系統,做過系統分析取捨之後,再翻開這本書會有一種醍醐灌頂的感覺。"
"關於資料庫,我看過最棒的一本書,作者能夠用非常簡單的方式,解釋複雜的技術,代表他對這項技術的確有深入的理解"
"對於技術詮釋的精采程度令人震驚!"
"可能是近15年來最好的技術書籍"






 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來