

 天天爆殺
天天爆殺  今日66折
今日66折 



















Ⓞ 16 堂課引領入門,學得會、做得順的絕佳教材!
Ⓞ最詳盡的深度學習基石書,CNN + RNN + GAN + DQN + DRL 各種模型學好學滿
初學者想要自學深度學習 (Deep Learning),可以在市面上找到一大堆「用 Python 學深度學習」、「用 xxx 框架快速上手深度學習」的書;也有不少書說「請從數學複習起!」,捲起袖子好好探究底層那些數學原理......但過早切入工具的學習、理論的探究,勢必對連深度學習的概念都還一知半解的初學者形成極大的學習門檻:
「我連什麼是深度學習?它是如何呈現、被使用的?都還模模糊糊,怎麼一下子就叫我 K Python、K 建模技術、K 數學......了?」
「程式號稱再怎麼短,始終還是讓人無感,模型跑出來準確率 95.7% → 96.3%...那就是深度學習的重點?」
【精心設計循序漸進 16 堂課,帶你無痛起步!】
為了徹底解決入門學習時的混亂感,本書精心設計循序漸進的 16 堂課,將帶你「無痛起步」,迅速掌握深度學習的重點。
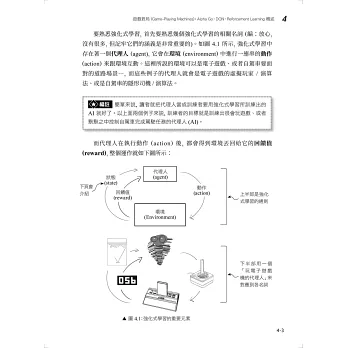
本書共分成 4 大篇、16 堂課。第 1 篇會利用 4 堂課 (零程式!零數學!) 帶你從深度學習在【機器視覺】、【自然語言處理】、【藝術生成】和【遊戲對局】 4 大領域的應用面看起,這 4 堂課不光是介紹,內容會安插豐富的線上互動網站,讓讀者可以實際上網操作,立刻體驗深度學習各種技術是如何呈現的。不用懂程式、啃理論,本篇適合任何人閱讀,絕對看得懂、做得順,可以對深度學習瞬間有感!
有了第 1 篇這些知識做為基礎,你就可以抱著踏實的心情跟著第 2~4 篇這 12 堂課一一學習 4 大領域背後所用的技術,包括卷積神經網路 (CNN)、循環神經網路 (RNN)、對抗式生成網路 (GAN)、深度強化式學習 (DRL)...等等。學習時我們選擇了馬上就可以動手的 Google Colab 線上開發環境搭配 tf.Keras 框架來實作,閱讀內文時請務必搭配書中提供的範例程式動手演練。期盼透過這 16 堂課的學習,能夠讓學習曲線平滑、順暢,不用迂迴曲折地浪費時間。
最後要說明的是,本書所有範例都是最精簡的版本,以方便引領讀者理解 AI 的原理。"師父領進門,修行在個人,AI 才在萌芽階段,以後海闊天空,鼓勵大家不斷精進、勇往直前!"
本書特色
□滿滿延伸學習教材
‧範例 + 旗標 Bonus 加值內容 → www.flag.com.tw/bk/st/F1383
‧作者深度學習系列教學影片 → reurl.cc/mLj7jV
‧更多互動學習資源 → 詳內文 16.6 節
□看得懂脈絡 – 不只通單一主題,也通學習脈絡
‧絕對看得懂的神經網路基礎,不被損失函數/梯度下降/反向傳播/正規化/常規化...一拖拉庫技術名詞搞的暈頭轉向!
‧各章章末提供新名詞脈絡整理,讓你隨時掌握學習視野!
□學得會技術 – 不只通技術,也通應用
‧先熟悉機器視覺、自然語言處理、藝術生成、遊戲對局 4 大領域的應用,對為何學深度學習更有感!
‧不急著 Coding、建模!上網就可以立即體驗生動的深度學習技術!
□做得出成果 – 不只通觀念,也通實作
Colab + tf.Keras 具體實踐 4 大應用,熱門深度學習技術學好學滿!
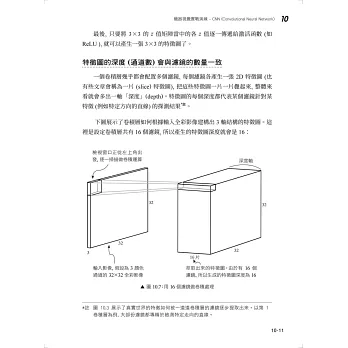
→機器視覺:CNN (卷積神經網路)
→自然語言處理:RNN (循環神經網路)
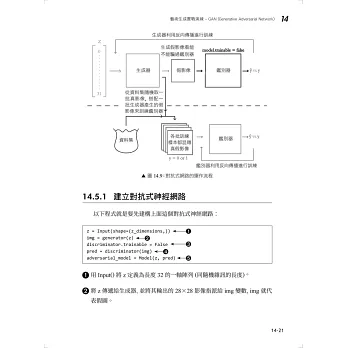
→藝術生成:GAN (對抗式生成網路)、DQN
→遊戲對局:DRL (深度強化式學習)
□詳細解說,流暢翻譯
本書由【施威銘研究室】監修,書中針對原書進行大量補充,並適當添加註解,幫助讀者更加理解內容!








 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來