

 天天爆殺
天天爆殺  今日66折
今日66折 


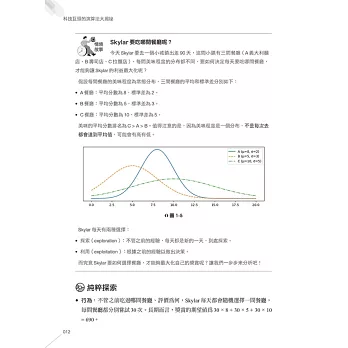
























♚瞭解資料科學:說明資料科學概念,深入淺出演算法
♚掌握實例應用:學習科技公司技術,掌握各種應用場景
♚運用實戰案例:涵蓋各種機器學習模型來打造實用功能
♚清楚內容編排:針對所需主題閱讀,充分理解演算法概念
【內容簡介】
本書內容改編自第14屆iThome鐵人賽AI& Data組的冠軍系列文章《那些在科技公司和App背後的資料科學》。你是否好奇全球頂尖的科技公司是如何利用資料科學打造出創新且成功的產品呢?本書將會深入介紹Spotify、Meta、Netflix、Uber和Airbnb等科技巨頭如何借助於資料科學和機器學習的技術,來為其產品注入革命性的創新。
本書整理及解析頂尖科技公司的機器模型與應用,內容從閱讀本書所需具備的概念開始,包括推薦系統、多臂式吃角子老虎機、A/B測試及排序模型的常見指標,再分別介紹科技巨頭的演算法內容,如Spotify和Netflix的多媒體內容推薦、Meta的社交內容推薦及排序、Airbnb的搜尋系統及房源排序模型、Uber和Uber Eats的預測模型及推薦系統等,我們將可瞭解這些演算法的理論知識,更可透過案例來學習這些模型是如何應用於實際產品之中。
【目標讀者】
✔想要對科技公司的演算法一探究竟的資料科學家。
✔想借鏡於頂尖科技公司如何利用資料科學,來改善個人的產品或服務的科技產業工作者。
✔想進一步發展自身技能的資料科學家和工程師。
✔對資料科學、科技和創新有濃厚興趣的讀者。
本書特色
學習頂尖公司的演算法與資料科學,啟發AI創新應用!
完整蒐集頂尖科技公司的演算法,學習AI世界的經驗精華!
全面解析及整理頂尖科技公司的機器學習模型,借鏡打造AI創新路徑!
專業推薦
「本書非常有結構地介紹現在科技巨頭賴以維生的各種推薦與媒合演算法。內容由淺入深地討論這些科技巨頭如何使用海量數據來揣度人心,闡釋為何看似相同的推薦與媒合問題在不同公司卻有本家家難念的經。」─ 黃從仁,國立臺灣大學心理學系模型建構與資訊學實驗室








 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來